蒋蒋的学习笔记
Qwen3VL推理详解
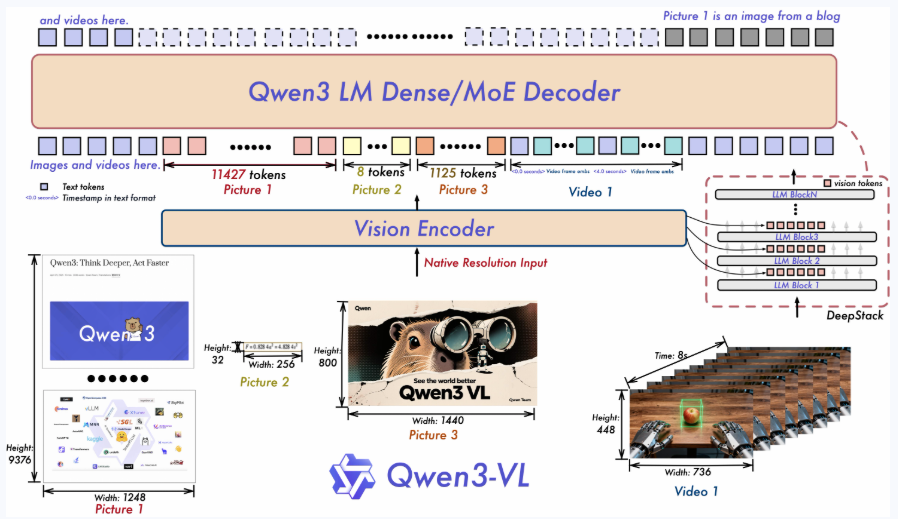
模型结构图
输入数据
{
"model": "qwen3vl",
"messages": [
{
"role": "user",
"content": [
{
"type": "video",
"video_url":
{
"url": "https://www.w3schools.com/html/movie.mp4"
}
},
{
"type": "text",
"text": "视频中发生了什么"
}
]
}
]
}
chat_template
- 参考视频:【rust本地化部署Qwen3-chat_template】https://www.bilibili.com/video/BV1xza1zKEEB/
tokenize
- 参考视频:【理解语言模型的分词-BPE算法】https://www.bilibili.com/video/BV1X882zVEUZ/
data preprocess
- Qwen2.5VL数据处理介绍:
- 参考博客: https://mp.weixin.qq.com/s/aEswVZN6wZqHmygh2Fcm-Q
- 参考视频:【qwen2.5vl数据处理】 https://www.bilibili.com/video/BV1qcp1zfE7M/
- 3与2.5的不同点:
- patch size大小从14变成16,smart_resize: 将图片宽高resize成与原宽高最接近的32的倍数
- <|video_pad|>填充:
<|im_start|>user <|vision_start|><|video_pad|><|vision_end|>视频中发生了什么<|im_end|> <|im_start|>assistant- video:处理时,根据视频时长和设置的帧率选取视频帧,示例视频:time=12.479s, fps=2, 选取的视频帧数为:25, 视频总帧数为374,从374里面选25张选取的帧间隔为15,选取的帧id为:[0, 15, 30, 45, …, 360],每一帧的时间戳就是 frame_id / fps,一共25个时间戳
- 考虑到后续patch_embed时t维度merge_size=2,
- 时间戳也要拿两帧取平均:[0.25025, 1.25125, …, 12.012]
- 视频tensor维度为:(t, h, w), 这里t已经把temporal_patch_size维度提出去了
- <|vision_start|><|video_pad|><|vision_end|>
<0.3 seconds><|vision_start|><|video_pad|>重复h*w次<|vision_end|> <1.3 seconds><|vision_start|><|video_pad|>重复h*w次<|vision_end|> ... <12.0 seconds><|vision_start|><|video_pad|>重复h*w次<|vision_end|> - 浮点数格式化时取的一位小数点
- 视频帧分开处理,使用它真实的时间戳,实现基于时间戳的精确事件定位,从而增强视频时间建模能力
- 输出维度: (t*h*w, 3*2*16*16=1536)
Qwen3VL model
vision encoder
patch embed
- 参考博客:【Qwen2.5VL视觉编码器PatchEmbed】 https://mp.weixin.qq.com/s/rYK6EeJo7W4UGQ57owqE0Q
- 参考视频:【qwen2.5vl-patch_embed】 https://www.bilibili.com/video/BV1jcp1zfEqt/
- 3与2.5的不同点:conv3d是有bias的
- 输出维度: (t*h*w, 1024)
pos embed
- 训练得到的位置嵌入 (2304, 1024)
- 如何让位置嵌入适应不同尺寸的宽高
- 双线性插值:对于图像上的任意一点,找到其周围最近的4个整数坐标点:左上/右上/左下/右下,然后根据距离远近对这4个点的值进行加权平均
- (t, h, w),假设(13, 16, 20)
- 等差数列生成h个(0..47)之间的数,计算向下/向上取整
- 等差数列生成w个(0..47)之间的数,计算向下/向上取整
- 整数部分
- 计算patch id: 每个图片帧共有h*w个patch块(16*20=320),patch_id = h_idx*width + w_idx
- w/h都向上向下取整了,两两组合得到(4,320)个patch_id
- 根据patch_id从pos_embed中拿到对应的嵌入:(4, 320, 1024)
- 小数部分
- 向下取整的小数部分:dh/dw = h_idx/w_idx - h_floor/w_floor
- 向上取整的小数部分: 1-dh/dw
- 将h方向和w方向对应位置的小数乘起来,两两组合得到(4, 320)
- 将整数部分得到的位置嵌入广播乘上小数部分的值
- 再将0维的四组数据逐元素相加,得到维度为(320, 1024)的数据
- 如果t>0,将上面的数据在0维重复t次,则得到(4160, 1024)的数据
- 考虑后续的merge操作,也需要reshape->(t, h / merge_size, merge_size, w / merge_size, merge_size, 1024)->(t, h, w, merge_size, merge_size, 1024)->(4160, 1024)
- 将相邻的块组合到一起,满足merge需要的数据要求
2dRoPE
- 参考博客:【Qwen2.5VL视觉编码器2DRoPE】 https://mp.weixin.qq.com/s/ZfkUeKj-6q7zvQsc2_FJUQ
- 参考视频:【qwen2.5vl-2dRoPE】 https://www.bilibili.com/video/BV17Fp1z8Eag/
- 3与2.5索引生成的方式不同
chunk attention
- 多张图片分块,每张图片分别做自注意力计算
- 图片与图片之间互相不干扰
- (t, h, w),假设(13, 16,20)
- q/k/v: (bs, n_head, seq_len, head_dim), seq_len = 13*16*20 = 4160
- cu_seqlens: [0, 320, 640, 960, 1280, 1600, 1920, 2240, 2560, 2880, 3200, 3520, 3840, 4160]
- 根据索引将q/k/v分成13个(bs, n_head, 320, head_dim)的Tensor
- 每份q/k/v分别做自注意力计算,最后将他们在seq_len维度上cat在一起
merge
- layernorm + linear1 + actfn + linear2
- deepstack merge
- deepstack_visual_indexes: [5, 11, 17]
- 融合多级 ViT 特征,以捕捉精细细节并锐化图像-文本对齐
- last merge
vision model
- depth: 24
- 输出:(vision_tokens, deepstack_feature_lists)
LM Dense Decoder
MRoPE
- 参考博客:【Qwen2.5VL语言模型】 https://mp.weixin.qq.com/s/ZfkUeKj-6q7zvQsc2_FJUQ
- 参考视频:【qwen2.5vl-2dRoPE】 https://www.bilibili.com/video/BV17Fp1z8Eag/
language model
- base model: Qwen3
- q/k norm
- 特殊处理
- 前三层decode layer的输出需要加上vision encoder中输出的deepstack_feature
LM MOE Decoder理解
- 参考博客:【MOE-混合专家模型】 https://mp.weixin.qq.com/s/HRjjxjRJ51UEgTCpiIN6jg
- 参考视频:【MOE混合专家模型介绍】 https://www.bilibili.com/video/BV1dtYAziEZv/
rust推理代码
https://github.com/jhqxxx/aha/tree/main/src/models/qwen3vl