蒋蒋的学习笔记
Qwen2.5VL数据处理
- chat_template
{ "messages": [ { "role": "user", "content": [ { "type": "image", "image": "file://./assets/ocr_test.png" }, { "type": "text", "text": "请分析图片并提取所有可见文本内容,按从左到右、从上到下的布局,返回纯文本" } ] } ] }
处理后内容:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>请分析图片并提取所有可见文本内容,按从左到右、从上到下的布局,返回纯文本<|im_end|>
<|im_start|>assistant
视频地址:rust本地化部署Qwen3-chat_template
- 预处理图像和视频
- 提取图像和视频:遍历messages,将content里面类型为image/image_url/video/video_url的路径提取出来
- 处理image
- 根据路径前缀,如”http://”, “https://”,”file://”,”data:image”,读取图片
- smart_resize: 将图片宽高resize成与原宽高最接近的28的倍数
- 为什么是28:
- 图像分块时,设置的块大小为14,
- 图像的相邻块会有融合操作,merge大小是2
- 28的倍数是为了保证上诉两个操作能正常进行
- 通道处理成rgb
- 维度(h, w, c)-> (c, h, w)
- 像素数据:(0-255的u8)-> (0,1的float/bfloat)
- normalize: 减去均值,再除以方差
- 维度 (c, h, w) => (1, c, h, w)
- repeat:(1, c, h, w) => (2, c, h, w): 适应3D卷积的时间维度
- 得到image tensor
- 处理video
- 读取视频
- 获取视频总帧数,帧率
- 根据帧数和帧率计算时长
- 根据时长和设置的fps提取图片
- smart_resize: 将每帧图片的宽高resize成与原宽高最接近的28的倍数
- 确定图片总数可以被temporal_patch_size整除,如果不可以需要重复最后一张图片至时间维度满足条件
- 维度:(t, c, h, w)
- 像素数据:(0-255的u8)-> (0,1的float/bfloat)
- normalize: 减去均值,再除以方差
- 得到video tensor
- 处理vision tensor
- 将输入维度(t, c, h, w)进行reshape和重排,处理成3D卷积以及merge操作需要的维度
- 3D卷积: in_channel=3, kernel_size:(2,14,14), out_channel=1280
-
merge-空间合并:将相邻的patch进行合并, 2*2=4 -> 1,减少序列长度,提高计算效率
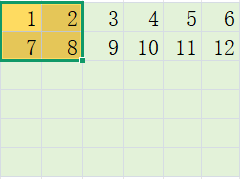
- 计算网格尺寸,可理解为对输入数据分块:
- 时间维度: temporal_patch_size=2,分块后: grid_t = t / temporal_patch_size
- h维度:patch_size=14, 分块后:grid_h= h / patch_size
- w维度:patch_size=14, 分块后:grid_w= w / patch_size
- h维度空间合并:grid_h / merge_size
- w维度空间合并:grid_w / merge_size
- reshape:( grid_t, temporal_patch_size, c, grid_h / merge_size, merge_size, patch_size, grid_w / merge_size, merge_size, patch_size )
- permute(vec![0, 3, 6, 4, 7, 2, 1, 5, 8]) => (grid_t, grid_h / merge_size, grid_w / merge_size, merge_size, merge_size, channel, temporal_patch_size, patch_size, patch_size)
- reshape( grid_t* grid_h * grid_w, c * temporal_patch_size * patch_size * patch_size)
- 返回reshape后的视觉数据和网格数据,即(grid_t, grid_h, grid_w)
- 如果有多个图像数据,在0维cat起来,得到拼接后的图像数据和图像网格数据
- 如果有多个视频数据,在0维cat起来,得到拼接后的视频数据和视频网格数据
- 如果有视频数据,计算一个grid_t代表多长时间,如果fps=2, temporal_patch_size=2, 那grid_t=1s,则一个网格时间代表1s,对于不同帧率视频,fps应该动态调整
- 将text中<|image_pad|>或者<|video_pad|>重复num_vision_token次
- 后续将使用真实的vision token embedding数据替换掉<|image_pad|>或<|video_pad|>的嵌入向量,因此需要保证替换索引是一致的
reshape时merge_size的必要性
参考视频:Qwen2.5-VL源码解读-Qwen2VLImageProcessor
import torch
t = torch.arange(0, 36).reshape(6, 6)
print(t)
t = t.reshape(3, 2, 3, 2)
print(t)
t = t.permute(0, 2, 1, 3)
print(t)
t = t.reshape(36)
print(t)
# merge操作需要将相邻的块进行融合,即[0, 1, 6, 7]merge成一个,[2, 3, 8, 9]merge成一个
# tensor([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11],
# [12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23],
# [24, 25, 26, 27, 28, 29],
# [30, 31, 32, 33, 34, 35]])
# 经过处理,tensor将相邻的块组合到一起,满足merge需要的数据要求
# tensor([ 0, 1, 6, 7, 2, 3, 8, 9, 4, 5, 10, 11, 12, 13, 18, 19, 14, 15,
# 20, 21, 16, 17, 22, 23, 24, 25, 30, 31, 26, 27, 32, 33, 28, 29, 34, 35])
rust代码
use std::collections::HashMap;
use candle_core::{D, DType, Device, Error, IndexOp, Result, Shape, Tensor};
use image::{DynamicImage};
use minijinja::{Environment, Value as MiniJinjaValue, context};
use tokenizers::Tokenizer;
use crate::{
config::VisionSetting,
qwen2_5_vl::utils::{
get_image, get_video_data, smart_resize,
},
};
#[derive(Clone)]
pub struct VisionInput {
pub data: Tensor,
pub grid_thw: Tensor,
}
#[derive(Clone)]
pub struct GeneralInput {
pub input_ids: Tensor,
pub attention_mask: Tensor,
pub cache_position: Tensor,
pub pixel_values: Option<Tensor>,
pub image_grid_thw: Option<Tensor>,
pub pixel_values_video: Option<Tensor>,
pub video_grid_thw: Option<Tensor>,
pub second_per_grid_ts: Option<Vec<f32>>,
}
pub struct Qwen2_5VLProcessor<'a> {
env: Environment<'a>,
pub tokenizer: Tokenizer,
vision_setting: VisionSetting,
device: Device,
dtype: DType,
image_token: String,
video_token: String,
}
impl<'a> Qwen2_5VLProcessor<'a> {
pub fn new(path: &str, template: &'a str, device: &Device, dtype: DType) -> Result<Self> {
// 加载分词器
let path = path.to_string();
assert!(
std::path::Path::new(&path).exists(),
"model path file not exists"
);
let tokenizer_file = path.clone() + "/tokenizer.json";
assert!(
std::path::Path::new(&tokenizer_file).exists(),
"tokenizer.json not exists in model path"
);
let tokenizer = Tokenizer::from_file(tokenizer_file)
.map_err(|e| Error::Msg(format!("tokenizer from file error{}", e)))?;
// 加载jinjaenv处理chat_template
let mut env = Environment::new();
// 添加自定义过滤器
env.add_filter("tojson", |v: MiniJinjaValue| {
serde_json::to_string(&v).unwrap()
});
env.add_filter("split", |s: String, delimiter: String| {
s.split(&delimiter)
.map(|s| s.to_string())
.collect::<Vec<String>>()
});
// 添加 lstrip 过滤器
env.add_filter("lstrip", |s: String, chars: Option<String>| match chars {
Some(chars_str) => s.trim_start_matches(chars_str.as_str()).to_string(),
None => s.trim_start().to_string(),
});
// 添加 rstrip 过滤器
env.add_filter("rstrip", |s: String, chars: Option<String>| match chars {
Some(chars_str) => s.trim_end_matches(chars_str.as_str()).to_string(),
None => s.trim_end().to_string(),
});
// let template = get_template(path.to_string())?;
let _ = env.add_template("chat", template);
let vision_setting = VisionSetting::default();
let image_token = "<|image_pad|>".to_string();
let video_token = "<|video_pad|>".to_string();
Ok(Self {
env,
tokenizer,
vision_setting,
device: device.clone(),
dtype,
image_token,
video_token,
})
}
pub fn apply_chat_template(&self, messages: &str) -> Result<String> {
let mes: serde_json::Value = serde_json::from_str(messages).unwrap();
let context = context! {
messages => &mes["messages"],
add_generation_prompt => true,
};
let template = self
.env
.get_template("chat")
.map_err(|e| Error::Msg(format!("render template error {}", e)))?;
let message_str = template
.render(context)
.map_err(|e| Error::Msg(format!("render template error {}", e)))?;
Ok(message_str)
}
pub fn text_encode(&self, text: String) -> Result<Tensor> {
let token_id = self
.tokenizer
.encode(text, true)
.map_err(|e| Error::Msg(format!("tokenizer encode error: {}", e)))?
.get_ids()
.to_vec();
let token_tensor = Tensor::from_slice(&token_id, (1, token_id.len()), &self.device)?;
Ok(token_tensor)
}
pub fn extract_vision_info(&self, messages: &str) -> Result<HashMap<String, Vec<String>>> {
let mes: serde_json::Value = serde_json::from_str(messages).unwrap();
let mut vision_map = HashMap::new();
vision_map.insert("image".to_string(), Vec::new());
vision_map.insert("video".to_string(), Vec::new());
if let Some(mes) = mes["messages"].as_array() {
for conversation in mes {
if let Some(content) = conversation["content"].as_array() {
for item in content {
if let Some(item_type) = item["type"].as_str() {
match item_type {
"image" | "image_url" => {
if item.get("image").is_some() {
if let Some(image_url) = item["image"].as_str() {
vision_map
.get_mut("image")
.unwrap()
.push(image_url.to_string());
}
}
if item.get("image_url").is_some() {
let image_url = &item["image_url"];
if image_url.get("url").is_some() {
if let Some(url) = image_url["url"].as_str() {
vision_map
.get_mut("image")
.unwrap()
.push(url.to_string());
}
}
}
}
"video" | "video_url" => {
if item.get("video").is_some() {
if let Some(video_url) = item["video"].as_str() {
vision_map
.get_mut("video")
.unwrap()
.push(video_url.to_string());
}
}
if item.get("video_url").is_some() {
let video_url = &item["video_url"];
if video_url.get("url").is_some() {
if let Some(url) = video_url["url"].as_str() {
vision_map
.get_mut("video")
.unwrap()
.push(url.to_string());
}
}
}
}
_ => {}
}
}
}
}
}
}
Ok(vision_map)
}
pub fn process_img(
&self,
img: &DynamicImage,
img_mean: &Tensor,
img_std: &Tensor,
) -> Result<Tensor> {
let img_h = img.height();
let img_w = img.width();
// h,w resize成 28的倍数
let (resize_h, resize_w) = smart_resize(img_h, img_w, &self.vision_setting, true, None)?;
let img = img.resize_exact(resize_w, resize_h, image::imageops::FilterType::CatmullRom);
let img_vec = img.to_rgb8().into_raw();
// (h, w, c) => (c, h, w)
let img_tensor = Tensor::from_slice(
&img_vec,
(resize_h as usize, resize_w as usize, 3),
&self.device,
)?
.permute((2, 0, 1))?
.to_dtype(self.dtype)?;
// 0-255 rescale to 0-1
let img_tensor = img_tensor.affine(1.0 / 255.0, 0.)?;
// normalize
let img_tensor = img_tensor
.broadcast_sub(&img_mean)?
.broadcast_div(&img_std)?;
// (c, h, w) => (1, c, h, w)
let img_tensor = img_tensor.unsqueeze(0)?;
Ok(img_tensor)
}
pub fn process_vision_tensor(&self, img_tensor: &Tensor) -> Result<(Tensor, Tensor)> {
let channel = img_tensor.dim(1)?;
let grid_t = img_tensor.dim(0)? / self.vision_setting.temporal_patch_size;
let grid_h = img_tensor.dim(2)? / self.vision_setting.patch_size;
let grid_w = img_tensor.dim(3)? / self.vision_setting.patch_size;
let shape = Shape::from(vec![
grid_t,
self.vision_setting.temporal_patch_size,
channel,
grid_h / self.vision_setting.merge_size,
self.vision_setting.merge_size,
self.vision_setting.patch_size,
grid_w / self.vision_setting.merge_size,
self.vision_setting.merge_size,
self.vision_setting.patch_size,
]);
let img_tensor = img_tensor.reshape(shape)?;
// shape to // grid_t,
// grid_h / merge_size,
// grid_w / merge_size,
// merge_size,
// merge_size,
// channel,
// temporal_patch_size,
// patch_size,
// patch_size,
let img_tensor = img_tensor.permute(vec![0, 3, 6, 4, 7, 2, 1, 5, 8])?;
let img_tensor = img_tensor
.reshape((
grid_t * grid_h * grid_w,
channel
* self.vision_setting.temporal_patch_size
* self.vision_setting.patch_size
* self.vision_setting.patch_size,
))?
.contiguous()?;
let grid_thw = Tensor::from_vec(
vec![grid_t as u32, grid_h as u32, grid_w as u32],
(1, 3),
&self.device,
)?;
Ok((img_tensor, grid_thw))
}
pub fn process_images(
&self,
imgs: Vec<DynamicImage>,
img_mean: &Tensor,
img_std: &Tensor,
) -> Result<VisionInput> {
let mut pixel_values_vec = Vec::new();
let mut vision_grid_thws_vec = Vec::new();
for img in imgs {
let img_tensor = self.process_img(&img, &img_mean, &img_std)?;
let img_tensor = Tensor::cat(&[&img_tensor, &img_tensor], 0)?.contiguous()?;
let (img_tensor, grid_thw) = self.process_vision_tensor(&img_tensor)?;
pixel_values_vec.push(img_tensor);
vision_grid_thws_vec.push(grid_thw);
}
let pixel_values = Tensor::cat(&pixel_values_vec, 0)?;
let vision_grid_thws = Tensor::cat(&vision_grid_thws_vec, 0)?;
Ok(VisionInput {
data: pixel_values,
grid_thw: vision_grid_thws,
})
}
pub fn process_videos(
&self,
data: Vec<Tensor>,
img_mean: &Tensor,
img_std: &Tensor,
) -> Result<VisionInput> {
let mut pixel_values_vec = Vec::new();
let mut vision_grid_thws_vec = Vec::new();
for single_video in data {
// 0-255 rescale to 0-1
let video_tensor = single_video.to_dtype(self.dtype)?.affine(1.0 / 255.0, 0.)?;
// normalize
let video_tensor = video_tensor
.broadcast_sub(&img_mean)?
.broadcast_div(&img_std)?
.contiguous()?;
let (video_tensor, video_grid_thw) = self.process_vision_tensor(&video_tensor)?;
pixel_values_vec.push(video_tensor);
vision_grid_thws_vec.push(video_grid_thw);
}
let pixel_values = Tensor::cat(&pixel_values_vec, 0)?.contiguous()?;
let vision_grid_thws = Tensor::cat(&vision_grid_thws_vec, 0)?.contiguous()?;
Ok(VisionInput {
data: pixel_values,
grid_thw: vision_grid_thws,
})
}
pub fn process_info(&self, messages: &str) -> Result<GeneralInput> {
let mut text = self.apply_chat_template(messages)?;
// let mut image_inputs = None;
let mut pixel_values = None;
let mut image_grid_thw = None;
let mut pixel_values_video = None;
let mut video_grid_thw = None;
// let mut video_inputs = None;
let mut second_per_grid_ts = None;
let vision_map = self.extract_vision_info(messages)?;
let img_mean =
Tensor::from_slice(&self.vision_setting.image_mean, (3, 1, 1), &self.device)?
.to_dtype(self.dtype)?;
let img_std = Tensor::from_slice(&self.vision_setting.image_std, (3, 1, 1), &self.device)?
.to_dtype(self.dtype)?;
for (key, vec) in vision_map {
println!("key: {}, \nvalue: {:?}", key, vec);
if key.eq("image") {
let mut file_vec = Vec::new();
for file in &vec {
let image = get_image(file);
match image {
Ok(img) => file_vec.push(img),
Err(e) => println!("get_image err: {:?}", e)
};
}
if file_vec.len() > 0 {
let vision_input = self.process_images(file_vec, &img_mean, &img_std);
match vision_input {
Ok(img_input) => {
pixel_values = Some(img_input.data);
image_grid_thw = Some(img_input.grid_thw);
},
Err(e) => println!("img process_images err: {:?}", e)
};
}
}
if key.eq("video") {
let mut file_vec = Vec::new();
for file in &vec {
let video_data = get_video_data(file, &self.vision_setting, &self.device);
match video_data {
Ok(tensor) => file_vec.push(tensor),
Err(e) => println!("get_video_data err: {:?}", e)
};
}
if file_vec.len() > 0 {
let vision_input = self.process_videos(file_vec, &img_mean, &img_std);
match vision_input {
Ok(video_input) => {
let video_num = video_input.grid_thw.dim(0)?;
pixel_values_video = Some(video_input.data);
video_grid_thw = Some(video_input.grid_thw);
let second_per_grid = vec![
self.vision_setting.temporal_patch_size as f32
/ self.vision_setting.fps;
video_num
];
second_per_grid_ts = Some(second_per_grid);
},
Err(e) => println!("video process_videos err: {:?}", e)
};
}
}
}
let merge_length = self.vision_setting.merge_size.pow(2);
if image_grid_thw.is_some() {
let mut index = 0;
while text.contains(&self.image_token) {
let grid_i = image_grid_thw.as_ref().unwrap().i(index)?;
let repeat_num =
grid_i.to_vec1::<u32>()?.iter().product::<u32>() as usize / merge_length;
let replace = "<|placeholder|>".repeat(repeat_num);
text = text.replacen(&self.image_token, &replace, 1);
index += 1;
}
text = text.replace("<|placeholder|>", &self.image_token);
}
if video_grid_thw.is_some() {
let mut index = 0;
while text.contains(&self.video_token) {
let grid_i = video_grid_thw.as_ref().unwrap().i(index)?;
let repeat_num =
grid_i.to_vec1::<u32>()?.iter().product::<u32>() as usize / merge_length;
let replace = "<|placeholder|>"
.repeat(repeat_num);
text = text.replacen(&self.video_token, &replace, 1);
index += 1;
}
text = text.replace("<|placeholder|>", &self.video_token);
}
let input_ids = self.text_encode(text)?;
let attention_mask = Tensor::ones_like(&input_ids)?;
let cache_position = Tensor::ones_like(&input_ids.i(0)?)?
.to_dtype(candle_core::DType::F64)?
.cumsum(D::Minus1)?
.to_dtype(candle_core::DType::U32)?
.broadcast_sub(&Tensor::new(vec![1_u32], input_ids.device())?)?;
let input = GeneralInput {
input_ids,
attention_mask,
cache_position,
pixel_values,
image_grid_thw,
pixel_values_video,
video_grid_thw,
second_per_grid_ts,
};
Ok(input)
}
pub fn token_decode(&self, tokens: Vec<u32>) -> Result<String> {
let decode = self
.tokenizer
.decode(&tokens, true)
.map_err(|e| Error::Msg(format!("tokenizer encode error{}", e)))?;
Ok(decode)
}
}